构建图书推荐系统 从KNN算法到矩阵分解的基础知识
随着数字阅读的普及,图书推荐系统已成为提升用户体验和促进书籍销售的关键工具。一个高效的推荐系统能够根据用户的兴趣和历史行为,智能地推荐他们可能喜欢的图书。在构建这样的系统时,有两种常见的基础算法:KNN(K-最近邻)算法和矩阵分解方法。本文将详细介绍这些算法的基础知识,并探讨如何将它们应用于图书推荐系统的构建。
一、推荐系统概述
图书推荐系统主要分为基于内容的推荐和协同过滤推荐。基于内容的推荐依赖于图书的属性(如作者、类别、关键词)与用户偏好的匹配;而协同过滤则利用用户-图书交互数据(如评分或购买记录)来预测用户兴趣。本文重点讨论协同过滤中的KNN算法和矩阵分解。
二、KNN算法在图书推荐中的应用
KNN算法是一种基于实例的学习方法,在推荐系统中常用于协同过滤。其思想是找到与目标用户或图书最相似的邻居,然后基于这些邻居的行为进行预测。
- 用户-用户KNN:计算用户之间的相似度(如余弦相似度或皮尔逊相关系数),基于相似用户的评分来预测目标用户对未评分图书的偏好。例如,如果用户A和用户B有相似的阅读历史,且用户B喜欢某本书,系统就可能推荐这本书给用户A。
- 图书-图书KNN:计算图书之间的相似度,例如基于用户评分向量。对于目标图书,找到其最相似的K本图书,然后推荐这些相似图书给曾对目标图书表示兴趣的用户。这种方法简单直观,适合处理小规模数据,但计算复杂度高,且可能面临数据稀疏性问题。
三、矩阵分解方法
矩阵分解是协同过滤中的高级技术,特别适用于处理大规模和稀疏的用户-图书交互矩阵。它将用户-图书评分矩阵分解为两个低维矩阵:用户特征矩阵和图书特征矩阵,从而捕捉潜在的用户兴趣和图书属性。
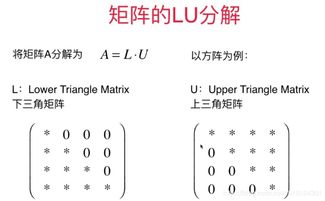
- 基本原理:给定一个用户-图书评分矩阵R(大小为m×n,其中m是用户数,n是图书数),矩阵分解旨在找到两个矩阵P(用户特征矩阵)和Q(图书特征矩阵),使得R ≈ P × Q^T。通过最小化预测评分与实际评分的误差(如使用均方误差),可以学习到这些特征。
- 优势与应用:矩阵分解能够有效处理数据稀疏性,并发现隐式特征(例如,某些图书可能属于“奇幻冒险”类别,而用户可能偏好该类)。在图书推荐中,系统可以根据分解后的特征预测用户对未读图书的评分,并生成个性化推荐。常用算法包括奇异值分解(SVD)和更高级的变体如SVD++。
四、KNN与矩阵分解的比较与集成
- KNN算法:实现简单,解释性强,适合冷启动问题(新用户或新图书),但计算开销大,且对数据稀疏敏感。
- 矩阵分解:可扩展性好,能捕捉复杂模式,但需要大量数据训练,且结果较难解释。
在实践中,可以将两者结合:例如,使用KNN处理新用户推荐,而矩阵分解用于优化整体系统性能。
五、构建图书推荐系统的步骤
- 数据收集:包括用户信息、图书元数据和交互数据(如评分、浏览历史)。
- 数据预处理:处理缺失值、归一化数据,并构建用户-图书矩阵。
- 算法选择:根据数据规模和业务需求选择KNN、矩阵分解或混合方法。
- 模型训练与评估:使用交叉验证和指标(如RMSE或准确率)评估性能。
- 部署与优化:将模型集成到系统中,实时推荐并收集反馈进行迭代改进。
六、总结
KNN算法和矩阵分解是构建图书推荐系统的两大基石。KNN以其简单性适用于快速原型开发,而矩阵分解则在处理大规模数据时表现出色。通过理解这些基础知识,开发者可以设计出高效的推荐系统,提升用户的阅读体验。未来,结合深度学习和实时数据处理,推荐系统将更加智能化和个性化。
如若转载,请注明出处:http://www.njshuoma.com/product/256.html
更新时间:2026-06-05 08:11:42